用語集
Glossary
データレイク(Data Lake)
データレイクとは多様なデータを「構造化データ」「非構造化データ」にかかわらず、そのままの形で貯蓄する仕組みです。
それぞれのデータを魚に見立て、データの湖にそのまま入れることをイメージするとわかりやすいかと思います。
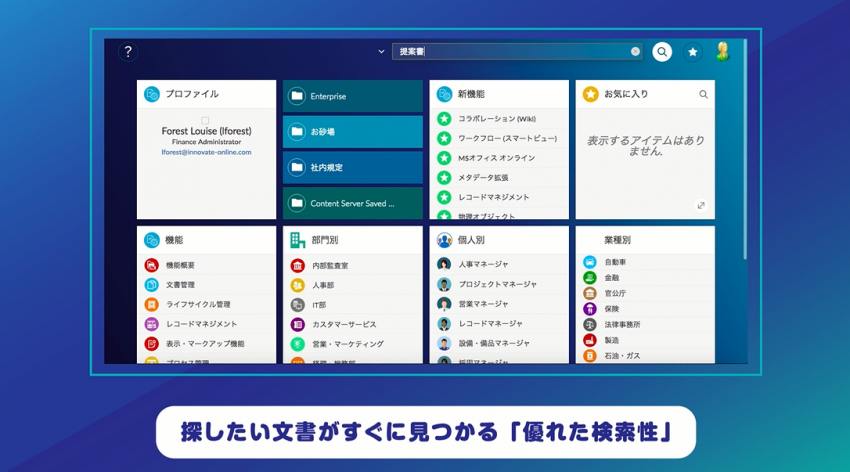
データレイクでは、すべてのデータを物理的な巨大ストレージで一元管理する必要はありません。分散処理と相性が良く、だれがいつどこにデータを発生させたのかを「データカタログ」によって管理します。ユーザーは使い慣れたポータルでデータカタログを利用しながら、必要なデータを自由に取り出して利用できます。分散管理とセルフサービス方式によって、IT部門にかかる負担を大幅に削減できるのが特徴です。
データレイクは大きく3つの要素で構成されます。「データ供給」と「データガバナンス」、および「データ処理」です。
「データ供給」では、データレイクに取り込むデータをいつ、誰が、どのように保存したのかを、はっきりとさせていなくてはなりません。そのデータについて、発生した時点から、データの更新や、データが取り出されるまで、いつ、誰が、何をしたのかしっかり管理するのが「データガバナンス」であり、このプロセスにデータカタログは不可欠です。
さらに、「データ処理」では、ユーザー自身がセルフサービス方式でデータ分析やデータ活用を行います。データレイクが提供するユーザー専用の分析スペースをサンドボックス(砂場)と呼ぶことがあります。
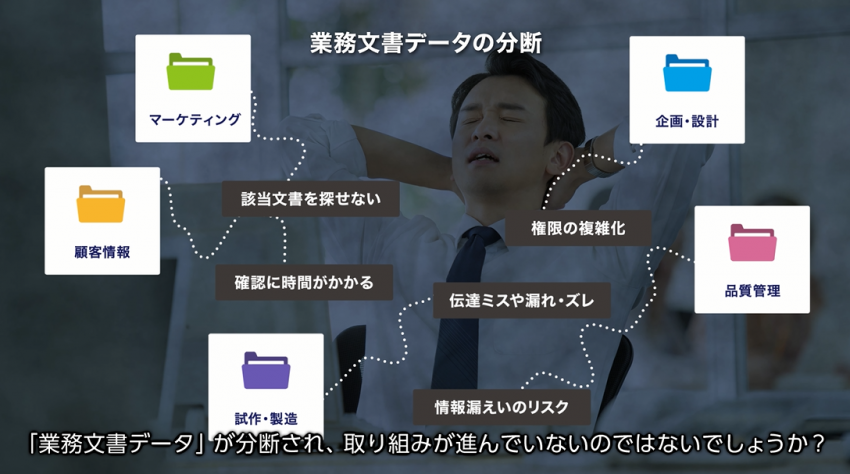
データレイクの構築にあたっては、まずは企業に関係するすべてのデータを貯蓄していく流れになります。データの品質を高めるクレンジングなどの作業が不必要になるわけではありませんが、まずは貯蓄することを優先します。そのため、信頼性の低いデータや古いデータなどが多く紛れ込むと、必要なタイミングで適切な情報を取り出すのが難しくなりがちです。
このような状態を「データスワンプ(データの沼)」といいます。湖の透明度が下がって泥のようになり、魚を見つけるのが困難になってしまうのです。
データスワンプを防ぐうえで、データカタログとそれを生成するカタログエンジンの良し悪しがポイントになってきます。
詳しくはこちらの記事も参照ください。
https://infogov-labo.jp/articles/what-is-a-data-lake-and-what-is-the-difference-from-a-data-warehouse/